Solution
The solution, called xprocedit [xprocedit], consists of an extension to the JointJS shape model in order to accommodate different kinds of XProc steps (atomic, compound, multicontainer; standard/user-defined), primary/non-primary ports, and options that act like input ports but are displayed differently and can have default values.
More details are given in one of the author’s master’s thesis [GeueMT].
XProc 3.0 is currently in the later stages of being specified. One XProc 1.0 concept that 3.0 does away with is parameter ports. It was decided that parameter ports will not be supported by xprocedit. However, for pipelines that don’t use parameter ports, an XProc 1.0 serialization is still available. This is because the generated pipelines need to be tested but XProc 3.0 processors are not widespread yet. Support for XDM 3.1 maps, which serve as a replacement for parameter ports when supplied as a parameter option, is currently being implemented in xprocedit. It should be possible, if users are interested and if funding is available, to use xprocedit as an XProc 1.0→3.0 migration tool, converting parameter ports to map options during import.
An issue where an interactive editor may help is validation, or rather, forcing the user to only create valid pipelines. Ideally, a graphical pipeline editor will not, for example, let users connect two steps with a directed edge that points from input to output, from input to input, or from a step to itself. Another check that is built into the tooling might prevent users from connecting an output port that may emit multiple documents to an input port that only accepts a single document. To that end, a certain amount of custom Javascript application logic had to be employed, and this is not finished yet. Verifying that the declared content types of an output port match the content types that an input port accepts is another future custom Javascript validation that is interesting in designing XProc 3.0 pipelines with their support for non-XML documents.
Some constraints, such as whether there are no loops in the pipeline or whether all required inputs are connected, are currently only checked upon export, via XSLT, and with poor error reporting.
As mentioned in the previous section, export from the internal Javascript model via its JSON serialization is performed
by XSLT 3.0 transformations in the browser, starting from the result of applying fn:json-to-xml() to the JSON
model.
The framework maintains an internal Javascript object representation of the graph. It was decided that the XProc XML document be generated from the JSON serialization of this model, rather than from the SVG rendering. The main reason is that, although the JSON representation also contains some layout information, it is considered as more stable than an SVG rendering. The tool that was chosen for generating the XProc XML document, Saxon-JS, supports XSLT 3 and XPath 3.1, and therefore it is equally capable of transforming JSON documents to XML as it is capable of transforming SVG to another XML vocabulary. What finally tipped the scale in favour of converting JSON rather than SVG to XProc was symmetry: There also needs to be an import process that imports pipelines and step libraries to the internal model, which is Javascript/JSON rather than SVG.
An important aspect when generating pipelines for future human editing in XML format is this: There can be multiple equivalent XML representations of a given graph. Consider the following pipeline (Figure 1, “A Simple XSLT Pipeline”, taken from [GeueMT]):
Figure 1. A Simple XSLT Pipeline
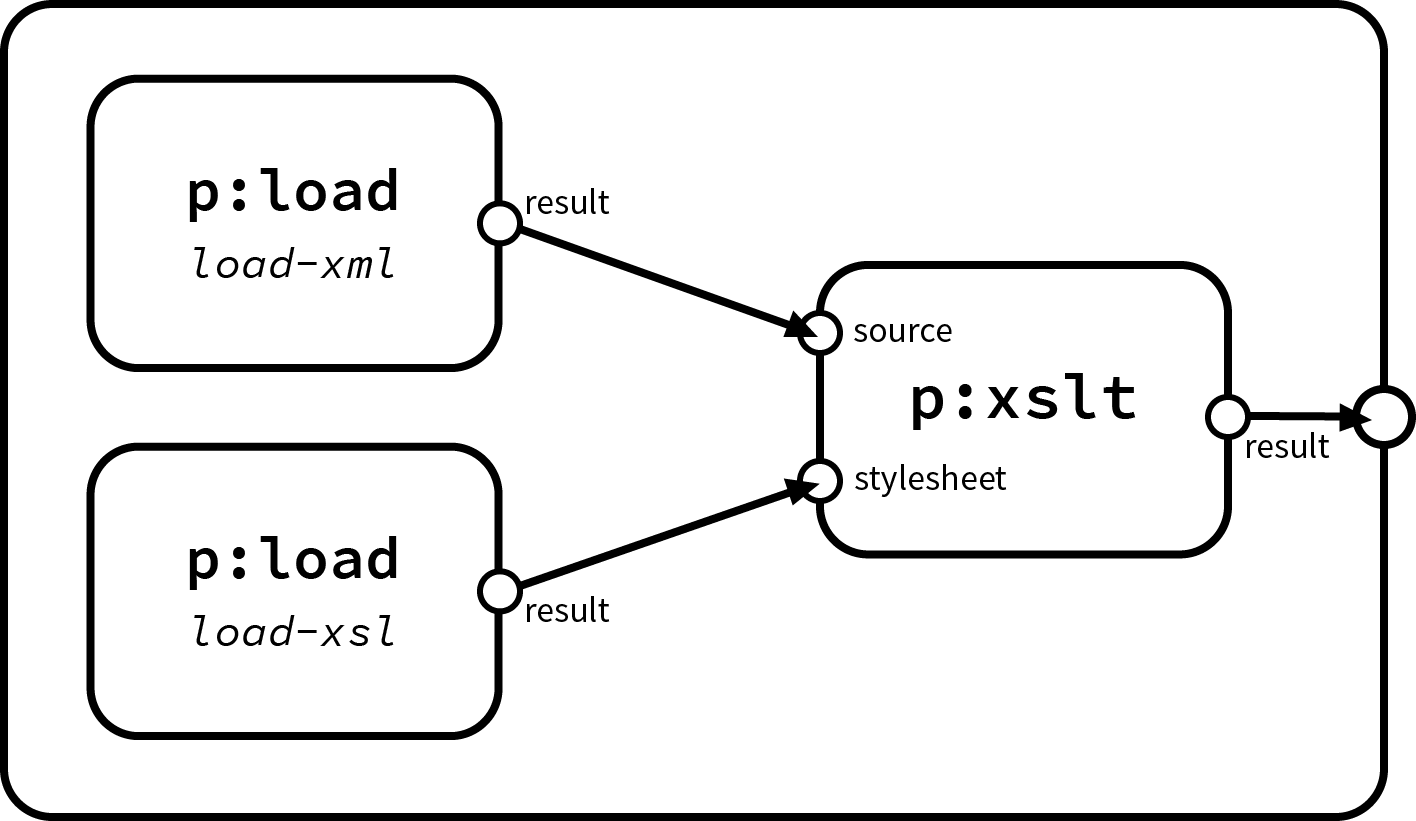
When serializing this pipeline as an XProc XML document, two variants are possible:
<p:declare-step xmlns:p="http://www.w3.org/ns/xproc" xmlns:c="http://www.w3.org/ns/xproc-step" version="1.0"> <p:output port="result" primary="true"/> <p:load name="load-xsl" href="test.xsl"/> <p:load name="load-xml" href="test.xml"/> <p:xslt> <p:input port="stylesheet"> <p:pipe port="result" step="load-xsl"/> </p:input> <p:input port="parameters"><p:empty/></p:input> </p:xslt> </p:declare-step>
and
<p:declare-step xmlns:p="http://www.w3.org/ns/xproc" xmlns:c="http://www.w3.org/ns/xproc-step" version="1.0"> <p:output port="result" primary="true"/> <p:load name="load-xml" href="test.xml"/> <p:load name="load-xsl" href="test.xsl"/> <p:sink/> <p:xslt> <p:input port="source"> <p:pipe port="result" step="load-xml"/> </p:input> <p:input port="stylesheet"> <p:pipe port="result" step="load-xsl"/> </p:input> <p:input port="parameters"><p:empty/></p:input> </p:xslt> </p:declare-step>
The first variant uses a connection between the primary output of the step named load-xml with the
primary input of the XSLT step, while the second variant serializes the p:load steps in reverse order and
therefore needs to insert a p:sink step in between, and it needs to connect the primary input of the XSLT
step, source, explicitly with the primary output, result, of load-xml.
Unless one wants to use the x-y-coordinates as an ordering hint, the graph editor does not provide clues about the
preferred serialization order for the p:load steps. One possibility that was quickly rejected was to use
another type of connectors in the 2-D graph that represent document order. The idea was rejected because it puts an
additional burden onto the user that seems unnecessary.
Generating a serialization that makes maximum use of primary port connections is an optimization problem. The author addressed it by a graph traversal that favours serializing primary ports adjacently when there are multiple choices. This is a heuristics that does not guarantee optimal results but solves this issue well enough.
The import mechanism has to deal with a problem that is also related to default readable ports: It needs to make implicit connections explicit for ports and also for options. The core of this problem has already been addressed in an XSLT-based XProc documentation tool whose normalized output will be converted to JointJS’s internal JSON graph model using Saxon-JS.
Sub-Graphs
The subpipelines of compound steps such as p:for-each are displayed in their own tabs. Some bookkeeping
in the Javascript application will make sure that they are included in the JSON representation upon export and that they
are removed when the placeholder block in the containing graph is removed. JointJS would have permitted in-place folding
of subpipelines, but expanding them would have quickly occupied much screen space and it would also have necessitated more
advanced auto-layout capabilities.
Auto-layout is currently being added to the editor, its primary application being rendering the pipeline and its subpipelines (in separate tabs) initially after loading an existing pipeline.
For round-tripping (import, edit, export, import, …), in order to spare users the ordeal of recreating a decent layout
in xprocedit over and over again, there is an option to preserve layout information in the serialized pipeline, using
XProc p:pipeinfo elements.
The application’s user interface is still under development; in March 2019 it looked like Figure 2, “User Interface”.
Figure 2. User Interface
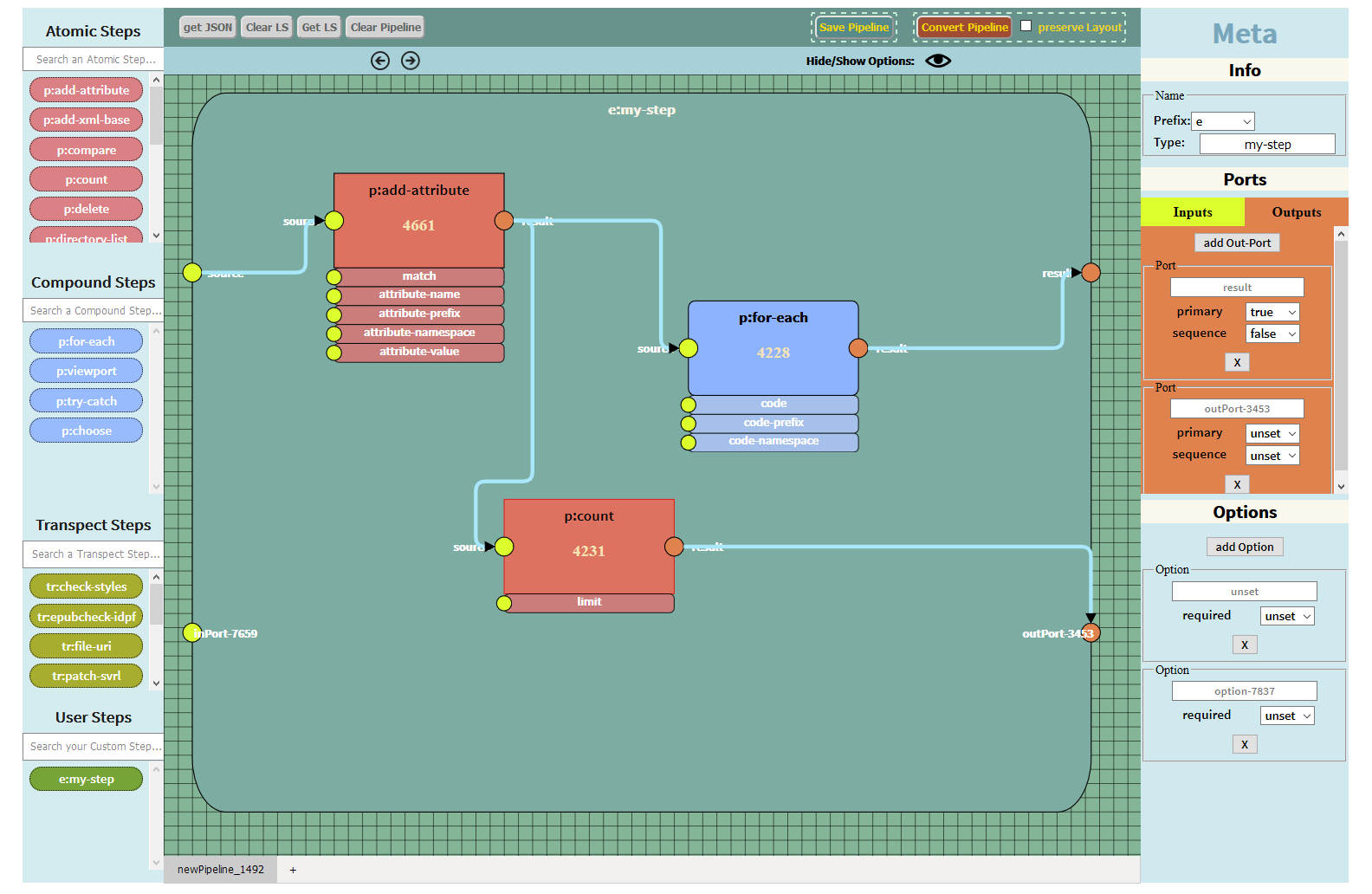
The step library palettes on the left are still supplied statically as JSON structures. There will be an import
process that processes p:import statements and makes available the imported steps, grouped by namespace
prefix. A difficulty that has already been solved is that imports often (in case of transpect, at least) use canonical
import URIs that are not identical with their locations on the Web server that xprocedit runs on. A catalog resolver
written in XSLT that runs in the browser will perform the required URI translations when recursively resolving the
imports, and it will also restore the canonical URIs when serializing the XProc XML from the internal
representation.